AI领域的白盒测试和自动debug
深度学习高速发展至今,难以debug和解释的问题,导致可重复性危机,因此AI debug显得越来越有需求。从工程角度看,算法开发人员很难解释新版模型比之前版本优异之处,模型在测试集上表现优异,但是线上表现仍然会让人担忧,因此模型的覆盖率白盒测试能帮助开发人员从不同的角度理解模型之间的差异性。在覆盖率指标基础上引入CGF技术,利用覆盖率帮助算法同学自动找模型bug,这对于类似自动驾驶等数据集收集难度大的场景帮助很大。本文结合近两年的论文,介绍一些自己在AI领域的白盒测试和自动debug的思考。
作者:张峰, 腾讯助理研究员 声明:本文为受邀发布,版权归作者所有
1. 背景
小明:“我们用同样结构的神经网络模型训练,你凭什么说你调的参数比我好?”
小红:“我的模型在测试集上不管是准确率还是auc值都比你高啊。”
小明:“呵呵,那你说你的模型究竟哪里比我的好,我看是测试集不够全面,不能测出我的模型的优异处,不信你再造一些测试集看看能不能找到我模型的bad case。”
小红:“你这凭什么说测试集质量好不好?”
简单的例子体现了目前DL模型应用场景的两个问题:
1. 同样结构,经过调参之后的模型差异在哪里?
2. 如何对模型进行自动化测试,特别是要求高的安全领域?
对于维护产品质量的测试同学来说,回答测试集质量如何的第一反应肯定是计算测试集合的覆盖率,一般可以简单认为经过覆盖率高的测试集验证后的软件,可靠性越高。但是传统意义上的代码覆盖率,并不能很好的评估测试集合的质量。与传统软件不同,DL 系统的大多数规则不是由程序员手工编写,而是从训练数据中学习,因此代码覆盖本身并不是评估 DL 系统覆盖率的一个好的度量标准。
和传统软件类似,在发展前期,我们需要主要关注的是功能的实现,但是随着不断的发展,对于模型测试环节的要求也越来越细化。针对神经网络模型的测试集合的覆盖率这一问题,研究最近的论文,指出可使用的一些覆盖率指标。
有了覆盖率指标之后,当然会想到更进一步,引入传统软件工程中的覆盖引导模糊测试方法,自动对模型进行debug.
本问将讲述覆盖率指标如何从白盒测试的角度理解模型之间的差异性,tensorfuzz和deepxplore等自动找bug的工具如何对模型自动测试。随着更多理论的发展,相信这些工具将会进一步为模型的可靠性保驾护航。当然眼下来讲,我们已经可以完成对模型可靠性的度量和找bug。
2.Deep Learning白盒测试--覆盖率
2.1神经元覆盖率
传统的代码覆盖率并不能很好的应用在模型分析中,Yinzhi Cao在deepxplore automated whitebox testing of deep learning systems中借鉴传统代码覆盖率概念,引进了神经元覆盖率的概念。deepxplore主要思想是引进差分测试的思想,可以应用在自动驾驶等领域中的白盒测试,自动化的生成bad case。文章发表在顶会sosp上,个人觉着文章针对deepp learning的系统测试提出了一个可靠的解决方案,而不是靠大量的人工标注数据进行测试,细节大家可阅读原文,本文则是根据其启发式生成bad case的指标—-神经元覆盖率,来评价测试集合的覆盖率。神经元覆盖率的定义很容易理解,如下图所示是个典型的DNN系统:
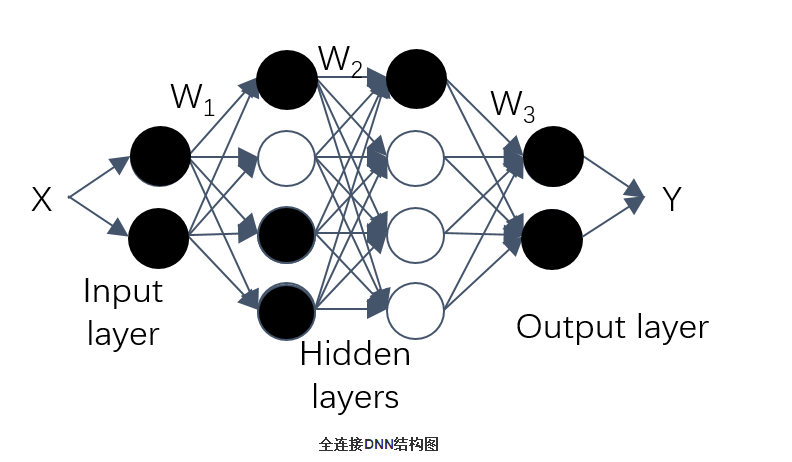
DNN每一层包含多个神经元,每个神经元都是一个包括激活函数的独立的计算单元,给定一个输入,输出对应的结果。常用的激活函数是sigmoid/tanh/RELU等,如下图所示:
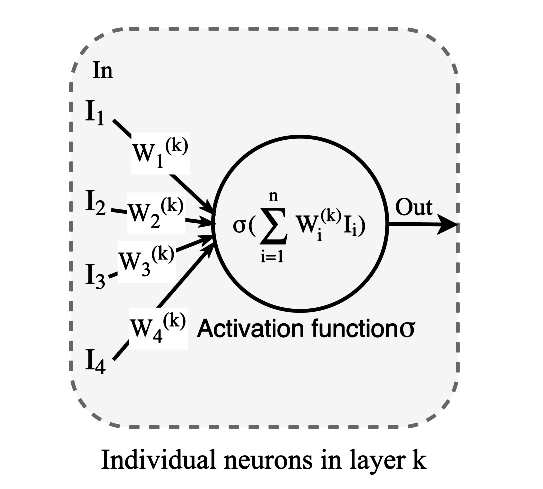
每一层的神经元都会提取特定的特征信息,然后传到更高层,这就类似传统软件的逻辑分支,如下所示:
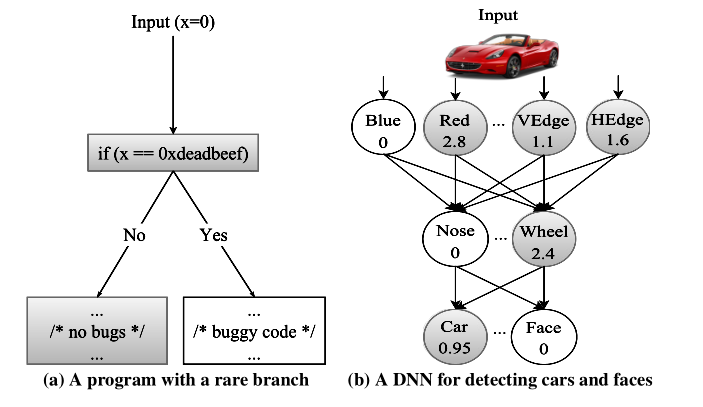
有了这样的认识,那么神经元覆盖率的定义也就很好理解了,被激活的神经元就是输出值大于阈值的单位,覆盖率就是被激活的神经元的占比。DNN所有神经元为集合N={n1,n2,...},测试集则为T={x1,x2,...}那么神经元n的输出就为 out(n,x)。neuron coverage就可以定义为:
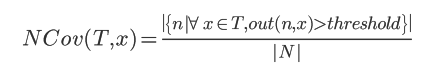
显然对于上图b的覆盖率就是5/8。
总结
由覆盖率的定义可以回答之前提出的第一个问题:同样结构,经过调参之后的模型差异在哪里? 调参之后,我们可以从覆盖的角度比较同样的测试输入,所激活的神经元的不同。从这一角度,可以给我们一个评判的标准,那就是每一层神经元所提取的特征,不同在何处。
2.2 MC/DC(Modified Condition/Decision Coverage)覆盖
代码覆盖率的概念被引入DL,那么传统软件发展至今,有着很多的指标,当然也可以类比引入。文章Testing Deep Neural Networks,类比航空领域测试指标MC/DC,MC/DC核心思想是构建一个使得分支条件中的布尔表达式中每个子条件都独立影响结果的测试集,即在其它所有条件不变的情况下改变该条件的值,使得判定结果改变。简单介绍如下,对于下列逻辑分支:
![]()
独立影响结果就是指的是,在两次测试中,所有的子表达式(假如三个)为FFT和FFF,那么可以说,第三个子表达式独立影响了结果。因此上式MC/DC覆盖率100%的测试案例是:

很显然。MC/DC覆盖率是比代码覆盖率要求更加严格的指标,那么类比于DNN中:
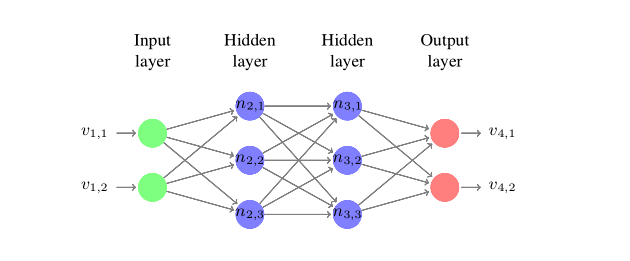
神经网络每一层都提取更高维的特征,也就是说,除了输入输出层,上一层的结果,是下一层神经元的条件输入,即n21,n22,n23 即为三个条件分支,三个神经元的符号为++-和+++并且n31符号也变化了,那么可以称n23独立影响了n31。
DNN中,相邻两层,两两构建神经元对,则覆盖率可以计算为:
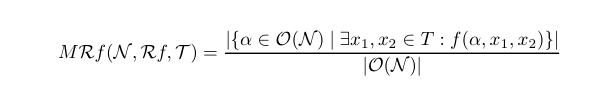
其中的分母即神经元对个数,分子则是独立影响神经元个数,显然上述的关键是如何定义神经元变化正—>负或者负—>正,u(x)表示经过激活函数之前的值,v(x)表示激活函数之后的值,x1,x2表示两个输入,这里主要引入了三种变化:
- sign change(sc(x1,x2)),简单来说,就是激活函数之后值不变的为+1,变化的为-1;
- value change,|u(x1)-u(x2)|>=d and !sc(x1,x2)即,x1和x2神经元sign都没变
- distance change,|u(x1)-u(x2)|<=d and sign(v,x1)=sign(v,x2),这边指的是一层的sign都不变的条件下,与value change不同的是vc指的是单个神经元,而dc则从整层角度出发。
3. tensorfuzz 神经网络自动debug工具
前文介绍了神经网络测试集的模型覆盖率计算方法,那么除了测试集覆盖率越高的测试集有着更好的测试能力,测试结果也更可靠之外,其实更重要的是能够帮助我们debug,自动找出bug。传统软件工程中覆盖引导模糊测试方法 coverage-guided fuzzing (CGF)被广泛用于bug发现,并且已被证明是行之有效的。覆盖引导模糊测试会尝试最大化程序的代码覆盖率,以便测试程序中存在的每个代码分支,显然关键在于如何计算coverage和fuzz输入。
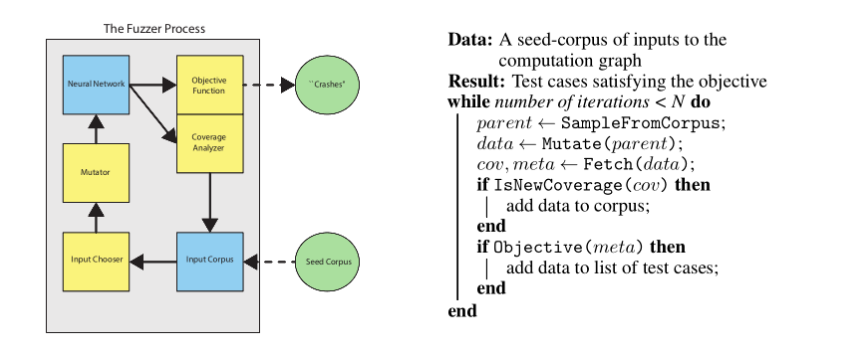
上图是google brain发表的论文TensorFuzz: Debugging Neural Networks with Coverage-Guided Fuzzing中的tensorfuzz流程图。
3.1 TensorFuzz介绍
tensorfuzz同样是首先需要定义一个覆盖率,文章分析了之前别人的工作,包括神经元覆盖率和MC/DC覆盖率,指出这几种覆盖在CGF中的劣势:
- 前面介绍的覆盖均为DNN覆盖
- 神经元覆盖率指标简单,容易100%,MC/DC则计算复杂不通用
前文也分析了,虽然这几种指标的提出,均为了能够自动找出bug,也就是根据bug的相似输入—》不同输出的特点,根据seed输入自动生成bug输入,tensorfuzz虽然也是同样的思想,但是其为了有着更广的适用性,因此设计出了一种更为简单的覆盖率计算指标。
覆盖率计算
一种简单朴素的想法是将网络中所有的激活向量进行比较,如果不一致,则认为输入产生了覆盖率的变化。但是这种方法很难使用,因为很简单,基本所有的输入都会导致变化。因此文章选择使用快速近似最近邻算法(Fast Library for Approximate Nearest Neighbors)FLANN来确定两组神经网络的“激活”是否有意义上的不同,也就是使用ANN找出最近的一组,计算距离是否大于阈值。对于ANN在此不多做介绍,可以参考相应论文。
mutate计算
mutate则是根据一定的规则,对于图像可能是加上高斯白噪声,对于字符文本可能是对于个别字符进行替换等,这样能够尽量保证输入类别不变。
实验结果
1.可以有效地发现训练好的神经网络中的数值误差
由于神经网络使用浮点数学,因此无论是在训练期间还是在评估期间,它们都容易受到数值问题的影响。众所周知,这些问题很难debug,部分原因是它们可能只由一小部分很少遇到的输入触发。这是CGF可以提供帮助的一个例子。我们专注于查找导致非数(NaN)值的输入。
2.反映了模型与其量化版本之间的分歧
通过检查现有数据几乎找不到错误:作为基线实验,我们使用32位浮点数训练了一个MNIST分类器(这次没有故意引入数值问题)。 然后,将所有权重和激活截断为16-bits,在MNIST测试集上比较了32-bit和16-bit模型的预测精度,没有发现不一致,但是,CGF可以快速地在数据周围的小区域找到许多错误。
3.揭示了字符级语言模型中的不良行为
作者运行了TensorFuzz和随机搜索进行测试,测试目的有两个,一是模型不应该连续多次重复相同的词,而是不应该输出黑名单上的词。测试进行24小时后,TensorFuzz和随机搜索都生成了连续重复的词。此外,TensorFuzz生成了十个黑名单词汇中的六个,而随机搜索只有一个
总结
神经元覆盖类比于代码覆盖,mc/dc覆盖则是引入了航空领域指标,两者覆盖越高,那么覆盖高的测试集可以被认为具有更好的测试能力,让用户更加相信这个测试集结果是比较可靠的。两种指标均适用DNN,在DL中还有大量场景使用的是CNN和RNN,这两种神经网络与DNN略有不同,但是我们完全可以将这两种指标引入。本文主要截取了覆盖率的定义,希望能量化测试集对于模型逻辑的测试充分程度,并且从覆盖激活的角度理解每次调参之后,模型的变化。
当然在测试环节,肯定最希望的是能够自动的debug,tensorfuzz计算简单,这意味着在大量的测试集情况下,该方法能够快速的找出bug,并且其通用性更广,有望能成为模型发布中的回归测试基础。
参考文献
- Pei K, Cao Y, Yang J, et al. DeepXplore: Automated Whitebox Testing of Deep Learning Systems[J]. 2017:1-18.
- Sun Y, Huang X, Kroening D. Testing Deep Neural Networks[J]. 2018.
- Odena A, Goodfellow I. TensorFuzz: Debugging Neural Networks with Coverage-Guided Fuzzing[J]. 2018.