『深度长文』Tensorflow代码解析(一)
转自: 姚健 深度学习大讲堂
2015年11月9日,Google发布深度学习框架TensorFlow并宣布开源,并迅速得到广泛关注,在图形分类、音频处理、推荐系统和自然语言处理等场景下都被大面积推广。TensorFlow系统更新快速,官方文档教程齐全,上手快速且简单易用,支持Python和C++接口。本文依据对Tensorflow(简称TF)白皮书[1]、TF Github[2]和TF官方教程[3]的理解,从系统和代码实现角度讲解TF的内部实现原理。以Tensorflow r0.8.0为基础,本文由浅入深的阐述Tensor和Flow的概念。先介绍了TensorFlow的核心概念和基本概述,然后剖析了OpKernels模块、Graph模块、Session模块。
1. TF系统架构
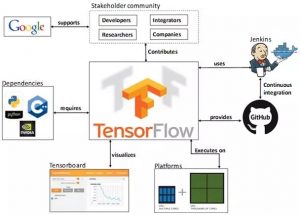
TF的依赖视图如图 2 1所示[4],描述了TF的上下游关系链。
TF托管在github平台,有google groups和contributors共同维护。
TF提供了丰富的深度学习相关的API,支持Python和C/C++接口。
TF提供了可视化分析工具Tensorboard,方便分析和调整模型。
TF支持Linux平台,Windows平台,Mac平台,甚至手机移动设备等各种平台。
1.2 TF系统架构
图 1 2是TF的系统架构,从底向上分为设备管理和通信层、数据操作层、图计算层、API接口层、应用层。其中设备管理和通信层、数据操作层、图计算层是TF的核心层。
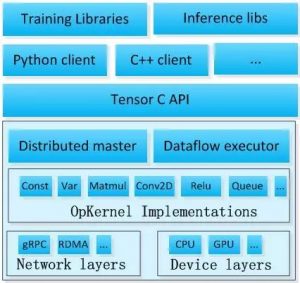
底层设备通信层负责网络通信和设备管理。设备管理可以实现TF设备异构的特性,支持CPU、GPU、Mobile等不同设备。网络通信依赖gRPC通信协议实现不同设备间的数据传输和更新。
第二层是Tensor的OpKernels实现。这些OpKernels以Tensor为处理对象,依赖网络通信和设备内存分配,实现了各种Tensor操作或计算。Opkernels不仅包含MatMul等计算操作,还包含Queue等非计算操作,这些将在第5章Kernels模块详细介绍。
第三层是图计算层(Graph),包含本地计算流图和分布式计算流图的实现。Graph模块包含Graph的创建、编译、优化和执行等部分,Graph中每个节点都是OpKernels类型表示。关于图计算将在第6章Graph模块详细介绍。
第四层是API接口层。Tensor C API是对TF功能模块的接口封装,便于其他语言平台调用。
第四层以上是应用层。不同编程语言在应用层通过API接口层调用TF核心功能实现相关实验和应用。
1.3TF代码目录组织
图 1 3是TF的代码结构视图,下面将简单介绍TF的目录组织结构。

Tensorflow/core目录包含了TF核心模块代码。
public: API接口头文件目录,用于外部接口调用的API定义,主要是session.h 和tensor_c_api.h。
client: API接口实现文件目录。
platform: OS系统相关接口文件,如file system, env等。
protobuf: 均为.proto文件,用于数据传输时的结构序列化.
common_runtime: 公共运行库,包含session, executor, threadpool, rendezvous, memory管理, 设备分配算法等。
distributed_runtime: 分布式执行模块,如rpc session, rpc master, rpc worker, graph manager。
framework: 包含基础功能模块,如log, memory, tensor
graph: 计算流图相关操作,如construct, partition, optimize, execute等
kernels: 核心Op,如matmul, conv2d, argmax, batch_norm等
lib: 公共基础库,如gif、gtl(google模板库)、hash、histogram等。
ops: 基本ops运算,ops梯度运算,io相关的ops,控制流和数据流操作
Tensorflow/stream_executor目录是并行计算框架,由google stream executor团队开发。
Tensorflow/contrib目录是contributor开发目录。
Tensroflow/python目录是python API客户端脚本。
Tensorflow/tensorboard目录是可视化分析工具,不仅可以模型可视化,还可以监控模型参数变化。
third_party目录是TF第三方依赖库。
eigen3: eigen矩阵运算库,TF基础ops调用
gpus: 封装了cuda/cudnn编程库
2. TF核心概念
TF的核心是围绕Graph展开的,简而言之,就是Tensor沿着Graph传递闭包完成Flow的过程。所以在介绍Graph之前需要讲述一下符号编程、计算流图、梯度计算、控制流的概念。
2.1 Tensor
在数学上,Matrix表示二维线性映射,Tensor表示多维线性映射,Tensor是对Matrix的泛化,可以表示1-dim、2-dim、N-dim的高维空间。图 2 1对比了矩阵乘法(Matrix Product)和张量积(Tensor Contract),可以看出Tensor的泛化能力,其中张量积运算在TF的MatMul和Conv2D运算中都有用到,
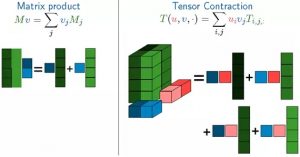
Tensor在高维空间数学运算比Matrix计算复杂,计算量也非常大,加速张量并行运算是TF优先考虑的问题,如add, contract, slice, reshape, reduce, shuffle等运算。
TF中Tensor的维数描述为阶,数值是0阶,向量是1阶,矩阵是2阶,以此类推,可以表示n阶高维数据。
TF中Tensor支持的数据类型有很多,如tf.float16, tf.float32, tf.float64, tf.uint8, tf.int8, tf.int16, tf.int32, tf.int64, tf.string, tf.bool, tf.complex64等,所有Tensor运算都使用泛化的数据类型表示。
TF的Tensor定义和运算主要是调用Eigen矩阵计算库完成的。TF中Tensor的UML定义如图 2 2。其中TensorBuffer指针指向Eigen::Tensor类型。其中,Eigen::Tensor[5][6]不属于Eigen官方维护的程序,由贡献者提供文档和维护,所以Tensor定义在Eigen unsupported模块中。
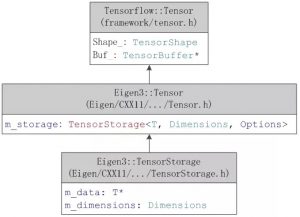
图 2 2中,Tensor主要包含两个变量m_data和m_dimension,m_data保存了Tensor的数据块,T是泛化的数据类型,m_dimensions保存了Tensor的维度信息。
Eigen::Tensor的成员变量很简单,却支持非常多的基本运算,再借助Eigen的加速机制实现快速计算,参考章节3.2。Eigen::Tensor主要包含了
一元运算(Unary),如sqrt、square、exp、abs等。
二元运算(Binary),如add,sub,mul,div等
选择运算(Selection),即if / else条件运算
归纳运算(Reduce),如reduce_sum, reduce_mean等
几何运算(Geometry),如reshape,slice,shuffle,chip,reverse,pad,concatenate,extract_patches,extract_image_patches等
张量积(Contract)和卷积运算(Convolve)是重点运算,后续会详细讲解。
2.2 符号编程
编程模式通常分为命令式编程(imperative style programs)和符号式编程(symbolic style programs)。
命令式编程容易理解和调试,命令语句基本没有优化,按原有逻辑执行。符号式编程涉及较多的嵌入和优化,不容易理解和调试,但运行速度有同比提升。
这两种编程模式在实际中都有应用,Torch是典型的命令式风格,caffe、theano、mxnet和Tensorflow都使用了符号式编程。其中caffe、mxnet采用了两种编程模式混合的方法,而Tensorflow是完全采用了符号式编程,Theano和Tensorflow的编程模式更相近。
命令式编程是常见的编程模式,编程语言如python/C++都采用命令式编程。命令式编程明确输入变量,并根据程序逻辑逐步运算,这种模式非常在调试程序时进行单步跟踪,分析中间变量。举例来说,设A=10, B=10,计算逻辑:
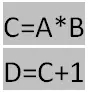
第一步计算得出C=100,第二步计算得出D=101,输出结果D=101。
符号式编程将计算过程抽象为计算图,计算流图可以方便的描述计算过程,所有输入节点、运算节点、输出节点均符号化处理。计算图通过建立输入节点到输出节点的传递闭包,从输入节点出发,沿着传递闭包完成数值计算和数据流动,直到达到输出节点。这个过程经过计算图优化,以数据(计算)流方式完成,节省内存空间使用,计算速度快,但不适合程序调试,通常不用于编程语言中。举上面的例子,先根据计算逻辑编写符号式程序并生成计算图

其中A和B是输入符号变量,C和D是运算符号变量,compile函数生成计算图F,如图 2 3所示。
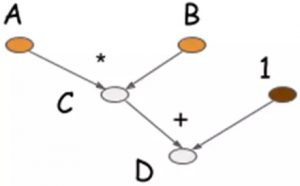
最后得到A=10, B=10时变量D的值,这里D可以复用C的内存空间,省去了中间变量的空间存储。
![]()
图 2 4是TF中的计算流图,C=F(Relu(Add(MatMul(W, x), b))),其中每个节点都是符号化表示的。通过session创建graph,在调用session.run执行计算。
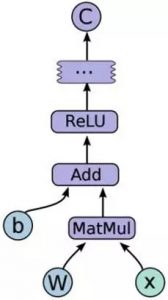
和目前的符号语言比起来,TF最大的特点是强化了数据流图,引入了mutation的概念。这一点是TF和包括Theano在内的符号编程框架最大的不同。所谓mutation,就是可以在计算的过程更改一个变量的值,而这个变量在计算的过程中会被带入到下一轮迭代里面去。
Mutation是机器学习优化算法几乎必须要引入的东西(虽然也可以通过immutable replacement来代替,但是会有效率的问题)。 Theano的做法是引入了update statement来处理mutation。TF选择了纯符号计算的路线,并且直接把更新引入了数据流图中去。从目前的白皮书看还会支持条件和循环。这样就几乎让TF本身成为一门独立的语言。不过这一点会导致最后的API设计和使用需要特别小心,把mutation 引入到数据流图中会带来一些新的问题,比如如何处理写与写之间的依赖。[7]
2.3 梯度计算
梯度计算主要应用在误差反向传播和数据更新,是深度学习平台要解决的核心问题。梯度计算涉及每个计算节点,每个自定义的前向计算图都包含一个隐式的反向计算图。从数据流向上看,正向计算图是数据从输入节点到输出节点的流向过程,反向计算图是数据从输出节点到输入节点的流向过程。
图 2 5是2.2节中图 2 3对应的反向计算图。图中,由于C=A*B,则dA=B*dC, dB=A*dC。在反向计算图中,输入节点dD,输出节点dA和dB,计算表达式为dA=B*dC=B*dD, dB=A*dC=A*dD。每一个正向计算节点对应一个隐式梯度计算节点。

反向计算限制了符号编程中内存空间复用的优势,因为在正向计算中的计算数据在反向计算中也可能要用到。从这一点上讲,粗粒度的计算节点比细粒度的计算节点更有优势,而TF大部分为细粒度操作,虽然灵活性很强,但细粒度操作涉及到更多的优化方案,在工程实现上开销较大,不及粗粒度简单直接。在神经网络模型中,TF将逐步侧重粗粒度运算。
2.4 控制流
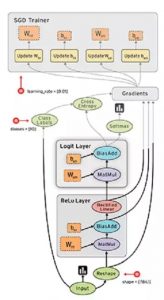
TF的计算图如同数据流一样,数据流向表示计算过程,如图 2 6。数据流图可以很好的表达计算过程,为了扩展TF的表达能力,TF中引入控制流。
在编程语言中,if…else…是最常见的逻辑控制,在TF的数据流中也可以通过这种方式控制数据流向。接口函数如下,pred为判别表达式,fn1和fn2为运算表达式。当pred为true是,执行fn1操作;当pred为false时,执行fn2操作。
![]()
TF还可以协调多个数据流,在存在依赖节点的场景下非常有用,例如节点B要读取模型参数θ更新后的值,而节点A负责更新参数θ,则节点B必须等节点A完成后才能执行,否则读取的参数θ为更新前的数值,这时需要一个运算控制器。接口函数如下,tf.control_dependencies函数可以控制多个数据流执行完成后才能执行接下来的操作,通常与tf.group函数结合使用。
![]()
TF支持的控制算子有Switch、Merge、Enter、Leave和NextIteration等。
TF不仅支持逻辑控制,还支持循环控制。TF使用和MIT Token-Tagged machine相似的表示系统,将循环的每次迭代标记为一个tag,迭代的执行状态标记为一个frame,但迭代所需的数据准备好的时候,就可以开始计算,从而多个迭代可以同时执行。
Report Story