您真正需要关注的AI 技术风向
“我们占据的位置并不重要,重要的是我们要去的方向”。本文总结了镖局眼中的AI技术趋势,仅一家之言,欢迎批评指正。作者:龙星镖局
更灵活的学习范式:无监督学习的黄金时代
现实中无标签数据的数据量远远超过有标签的数据,不使用这些数据是一种极大的浪费,不少大佬都曾大声疾呼要重视再重视无监督学习。2016年Yann LeCun大佬曾在NIPS上用一个蛋糕图指出无监督学习才是那个CAKE,也给大家挖了一个无监督学习的大坑。然而,无监督学习是很困难的,相较于监督学习往往也比较低效。一个自然的想法是如果我们能以低成本的方式给无标签数据打上标签,再用有监督的方式训练不就好了么?于是,自监督学习方法横空出世。自监督方法可以看作是披着无监督外壳的监督学习法,只不过Label是人们根据数据的特性伪造出来的。自监督学习由于其有效性,立马成为AI领域的风向标之一。
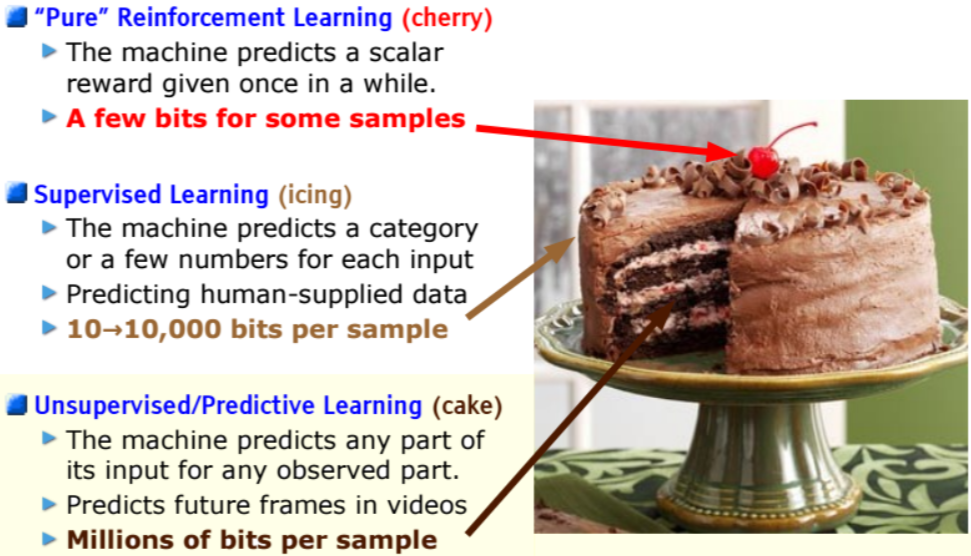
LeCun之所以在五年前提无监督学习的重要性,并不完全在于大佬的高瞻远瞩,实际上当时已经有部分工作证明了其有效性,大佬敏锐地发现它就是那个“星星之火”。Word2vec在2013年就被发明出来,很快就广泛应用于各种主流NLP任务上,带来效果的显著提升。虽然word2vec只是使用简单得不能再简单的神经网络,但它证明了这个范式的可行性。后面的Glove、ELMo、GPT、BERT则是不断用更大、更深的网络把它变得更有战斗力。在文本之外的图像领域,这个范式进展稍晚,但也在最近陆续发明出无监督学习大法,如MAE、MoCo等。回过头看不禁感叹大佬就是大佬,无监督学习真的“可以燎原”。
更大容量的模型:进入十万亿参数时代
虽然深度学习work的原理还未完全摸清,但应用中人们发现了一个定律:更大的模型,更好的效果。2018年的BERT只有1.1亿参数,2019年的GPT-2达到15亿参数,随后的MegatronLM的参数更是突破83亿。不断变大的模型一次次刷新基线,各大厂商的军备竞赛也白热化,如今每半年模型的容量差不多就能提升10倍。2020年具备170亿参数的Turing-NLG问世,GPT-3则更上一层楼,参数来到1750亿。千亿参数的模型很快就成为过去式,随后的Switch Transformer参数突破16000亿,而中国出品的悟道2.0则突破了17500亿,最近阿里的M6更是一举将参数规模提升到十万亿。
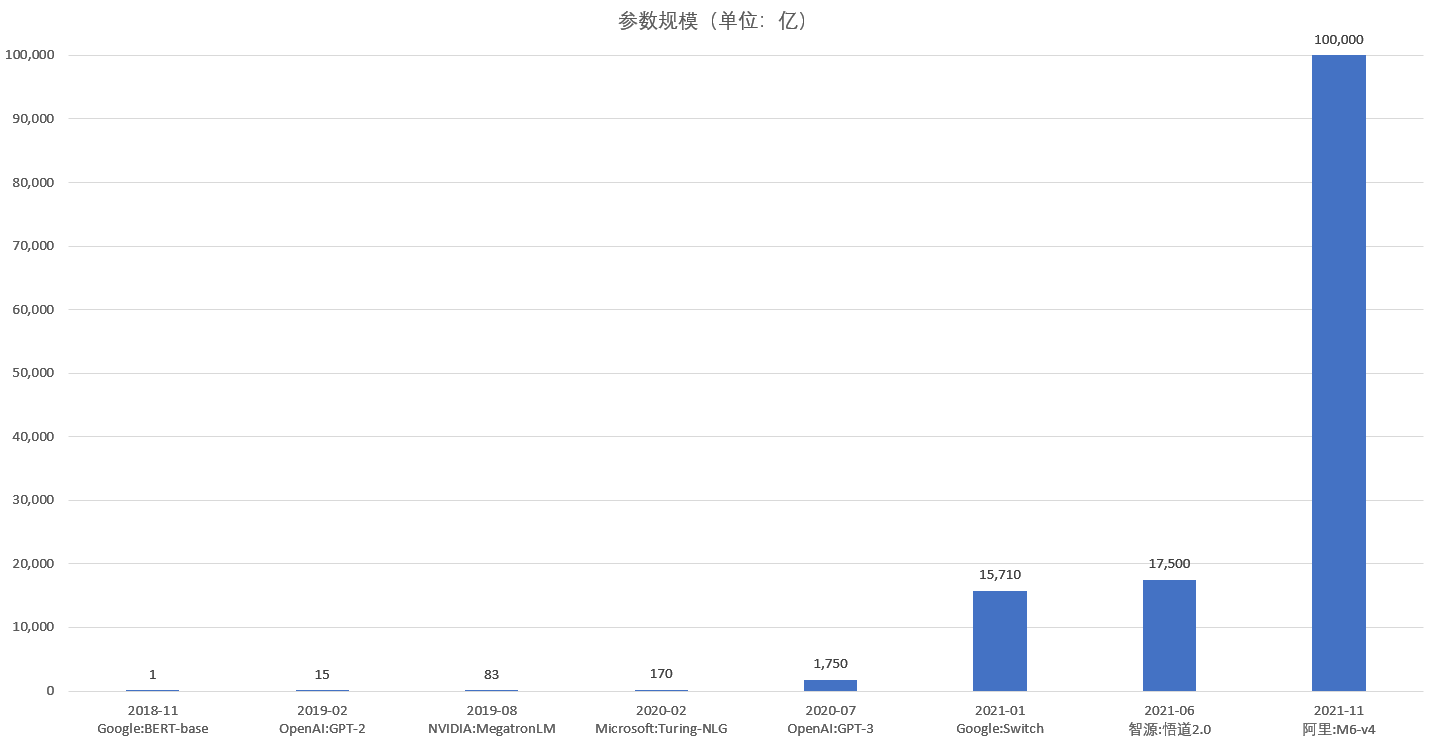
伴随着效果提升的同时,也引起大家对能源消耗的关注。以具有1750亿参数的GPT-3为例,有团队在Nvidia GPU集群组成的超算中心上测算,训练一次GPT-3消耗的电量约为19000度。按照美国的碳排放标准计算大约会产生8.5吨二氧化碳,相当于一辆汽车行驶70多万公里,往返地球和月球一次的排放量。巨大的能源消耗促使研究人员对性能和架构不断进行优化,最新的M6声称仅使用512张GPU即可在10天内训练出有100000亿参数的模型。相比去年OpenAI发布的同等规模的GPT-3,其能量消耗仅为1%。可以预见,节能减排未来将会是AI领域的一大新风向。
更适配的对接:从fine-tuning到prompt
基于大量数据预训练后,数据中蕴含的信息就被编码到了模型中,类似人们脑海中的知识。而这里的知识很广泛,当面对一个新任务时,如何有效激活适合该任务的部分就成了关键。为方便叙述,我们对任务进行一下区分:预训练是上游任务,实际要解决的任务是下游。上下游的目标往往是不太一致的,预训练一般是个语言模型(最大化句子的概率),而下游任务可能是个句子分类的任务(最大化分类正确的概率)。将上游的知识应用到下游中的常用做法是fine-tuning,中文叫“微调”。但微调并没很好解决下游任务适配上游的问题,因为微调的流程是严格的“上游->知识->下游”,上下游之间被的模型(知识)隔离开了,这就有可能导致下游使用知识成本过高或者效果不好。
近年来,一个直觉上更好对接上下游的方式prompt被提出来,中文叫“提示”。不同于fine-tuning上下游完全隔离的模式,prompt反其道而为之,通过改造下游任务让其更像上游任务,以减少中间知识传递的损失。Prompt通过给上游任务一些线索,让它更好地理解我下游任务究竟想干什么。比如观点分类问题,输入是:“今天看了镖局关于技术趋势的文章,很受启发,太赞了。先点赞收藏,再转发扩散。”模型输出是:“正向/反向”。Prompt通过模板给一些线索,把下游任务的输入变成:“今天看了镖局关于技术趋势的文章,很受启发,太赞了。先点赞收藏,再转发扩散。这是篇____文章”。预训练模型就会在下划线处填上合适的候选词,可能是“很好的”、“不错的”、“精品”等等,通过这些候选词就可以映射到“正向”这类上。同样的,其他下游任务都可以通过模板和映射做些适配,这样下游任务就能得到更好的结果。直觉上prompt确实比fine-tuning更说得通,但其中需要很多的精心设计,和搞特征工程差不多。
更相似的算法:Transformer is all you need
Transformer是《Attention is All You Need》中为机器翻译任务所设计的模型结构,随后其中的Encoder在NLP预训练任务中大放异彩,成为BERT、GPT等的标配,快速取代了RNN的地位,独霸NLP领域。而此时,CNN还一直是CV领域的主流模型。从2020年开始有人进行跨界,尝试把Transformer引入CV领域,从此CVer就深深爱上了她,爱得是如痴如醉,欲罢不能。现在再看CV领域的会议,基本上都是Transformer在攻占CNN的阵地,如图像分类中的ViT、图像预训练中的MAE、目标检测中的DETRact、语义分割的SETR、图像生成中的GANsformer等等。
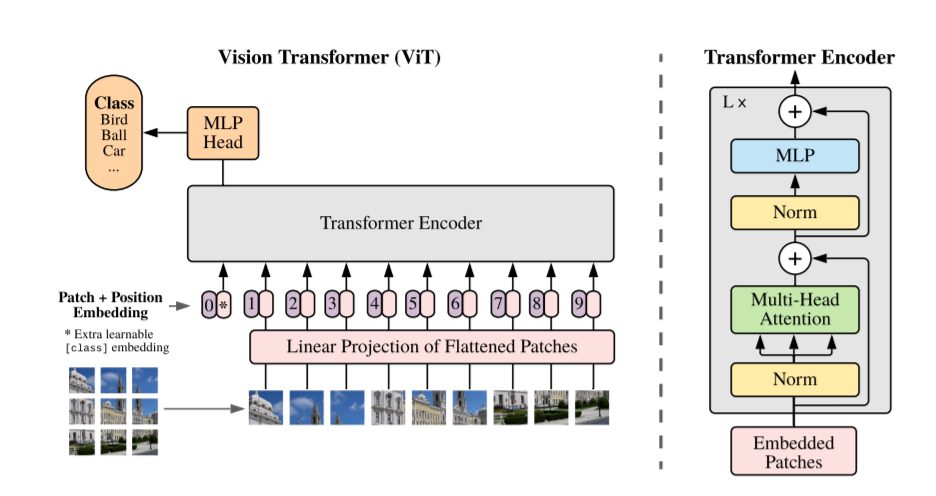
在工业界还有其他形式的数据,transformer对他们的训练能否有帮助呢?答案是Yes。在搜广推场景中,通过引入transformer结构,能更好拟合用户的兴趣,达到更好的建模效果。这里本质上是把用户的行为当作一个类似文本的序列,自然就可应用transformer大法了。在图数据上,DeepMind发表了Nature封面文章AlphaFold2,其中核心部件也有transformer的影子。MSRA团队用transformer夺得第一届图神经网络竞赛OGB Large-Scale Challenge图预测任务的冠军,还证明了Transformer实际上是表达能力更强的图神经网络,并且主流的图神经网络算法都可以看作是Transformer的特例。

值得一提的是,学术界的大佬们也发现把NLP中的方法照搬到CV的势头太明显,觉得这样不够有面子,不禁在问出一个问题:图像、语音任务上非要有一股NLP味儿吗?于是有人就开始研究如何用一个框架来统一文本、图像、语音等多个模态。这样一旦一个领域有新的方法涌现,就可以更加方便得在其他领域进行尝试落地,如Meta刚提出来的Data2Vec就是干这个事情的。注意,这里的多模态和常说的多模态学习是不同的,这里更关注如何把不同模态的学习目标和方式统一成一个范式,而不在于如何利用不同模态的数据得到更好的训练效果。
更个性化的模型:千人千模
千人千面是推荐产品中常用的术语,旨在表示为不同用户提供不同的推荐结果,更个性化的体现个体差异。如果把模型也当作一个产品,我们希望模型也能根据用户、场景的差异,提供更加个性化的模型服务,这就是所谓的千人千模。初听这个概念还有点困惑:一般的模型只要输入不同的特征不就实现了模型输出的个性化了,为什么还需要在模型层面单独体现个性化的差异呢?为更好理解千人千模,镖局建议你先忘记自己的身份,且听我慢慢道来。
要想实现个性化的模型,我们可以在特征上做些文章,把个体相关的年龄、性别、兴趣、用户ID给输进去,但是暴力丢进去不做任何处理效果往往不如预期。从本质上再次思考这个问题,如果为每一个用户定制一个独立的模型,不就好了么?理论上是可以的,但实际上这样学习的效果是不行的,因为一个用户的行为很少的,这样也没法用相似用户的行为来帮助其学习了。如此看来,这两种做法成了事情的两个极端,那能否做个平衡呢?抛开过去的经验不讲,自然的想法是不是先学一个通用的模型,再针对个体做些个性化微调是不是就好了?是的,近期在搜广推中大家开始引入LHUC来定制个性化的模型。在语音识别中,LHUC为每个说话者学习一个Hidden Unit Contribution,可以在通用模型的基础上融入单个个体的特性,进而达到更好的识别效果。
更低的入门门槛:进入自助化时代
十年前,业界主流的算法可能还是LR、SVM、决策树,但这并不代表当时没有其他效果更好的算法。实际上那个时候GBDT、MLP之类的算法也已经发明出来,但在工业界应用的门槛还相对较高,尝试实验的代价也较大。后来,伴随着XGBoost、Caffe、TensorFlow、PyTorch等框架的兴起,业界算法也很快进行了更新换代,而如今一个新算法发明后进入工业界落地的速度更是快得超出想象。工具和框架越来越发达,使用AI技术上手解决实际问题的门槛急剧下降,低代码甚至无代码正在成为趋势。

除了配套的工具和框架之外,学习新算法知识的门槛也大幅降低。如果想系统学习相关知识,除了之前搜索下来自己研读之外,现在又不少其他不错的方式出现,比如《跟李沐学AI》、业界的公开课、MOOC等。近期国内甚至还出现了像ReadPaper这样专门配套的论文阅读平台,再加上国内一些AI自媒体、AI社区组织的分享、翻译、资讯等形式,好多人都能更快感受AI技术的进展。毫不夸张地说,AI应用已进入自助化时代。
融合之美:结合领域知识的算法设计
统计机器学习要想工作就要有足够的数据进行训练,而大数据再大也是不够的。首先,当前很多大模型实验已经证明,如果能提供更多的数据、训练更多的轮数,算法不做任何改造还能继续提升效果,并未达到人们常说的”收敛“状态;其次,大数据到细分case时总是小的,比如推荐里某个不活跃用户、某个新的Item。最后,更多的数据往往意味着更多的参数,会给训练本身带来难度。而领域知识是人对问题认知的总结,其信息密度远大于原始数据。如果能将领域知识引入到算法设计中,就能更好地解决上述问题。比如黄埔军校MSRA近期就利用图像local相似性发明了基于Shifted Windowing的分层Transformer,一举夺得ICCV 2021最佳论文。可以预见,未来在更多任务上将会有更多融入领域知识的算法出现。
“世界上最重要的事,不在于我们在何处,而在我们朝着什么方向走”。希望本文给能大家一些方向的指引。祝各位朋友新年快乐!如果您觉得本文还不错,欢迎转发扩散,谢谢。
文中部分配图来自以下链接:

1 Comment