科普联邦学习
来源: 中国计算机学会
作者:杨强、刘洋、陈天健、童咏昕
2016 年是人工智能在世界范围内真正星光闪耀的一年。伴随着 AlphaGo 接连战胜两位人类顶尖围棋职业选手,我们看到了人工智能迸发出的真正的巨大潜力,也更加憧憬人工智能技术可以在无人车、医疗、金融等更多、更复杂、更前沿的领域施展拳脚。但是,当我们回顾人工智能的发展时,却难免心怀忐忑:人工智能的发展已经经历了两次低谷和三个高峰,会不会出现下一次低谷?又会在什么时候出现?
人工智能的两次低谷是由于算法、算力和数据的缺乏造成的,而当下借助大数据环境驱动的人工智能已经进入了第三个黄金发展时期。2016 年的 AlphaGo 是典型的例子,总计使用了 30 万盘棋局作为训练数据,并且取得了良好的效果。由此,人们希望像 AlphaGo 这种大数据驱动的人工智能能在各行各业得以应用。但是真实情况却让人非常失望:除了有限的几个行业,更多领域存在数据有限且质量较差的问题,不足以支撑人工智能技术的实现。同时,数据源之间存在难以打破的壁垒。一般情况下,人工智能所需要的数据涉及多个领域,例如在基于人工智能的产品推荐服务中,产品销售方拥有产品的数据、用户购买商品的数据,但是没有用户购买能力和支付习惯的数据。在大多数行业中,数据是以孤岛的形式存在的,由于行业竞争、隐私安全、行政手续复杂等问题,即使是在同一个公司的不同部门之间,实现数据整合也面临着重重阻力,在现实中将分散在各地、各个机构的数据进行整合几乎是不可能的,或者说所需的成本是巨大的。
另一方面,随着大数据的进一步发展,重视数据隐私和安全已经成为了世界性的趋势。每一次用户数据的泄露都会引起媒体和公众的极大关注,例如最近 Facebook 的数据泄露事件就引起了大范围的抗议行动。同时,各国都在加强对数据安全和隐私的保护。以欧盟在 2018 年 5 月 25 日开始实施的《通用数据保护条例》(General Data Protection Regulation, GDPR) 为例,GDPR 旨在保护用户的个人隐私和数据安全,它要求经营者用清晰、明确的语言来表述自己的用户协议,并且允许用户执行数据「被遗忘」的权利,即用户可以要求经营者删除其个人数据并且停止利用其数据进行建模,而违背该条例的企业将会面临巨额罚款。同样,中国在 2017 年起实施的《中华人民共和国网络安全法》和《中华人民共和国民法总则》也指出,网络运营者不得泄露、篡改、毁坏其收集的个人信息,并且与第三方进行数据交易时需确保拟定的合同明确约定拟交易数据的范围和数据保护义务。这些法规的建立在不同程度上对人工智能传统的数据处理模式提出了新的挑战。
在人工智能领域,传统的数据处理模式往往是一方收集数据,再转移到另一方进行处理、清洗并建模,最后把模型卖给第三方。但随着法规完善和监控愈加严格,如果数据离开收集方或者用户不清楚模型的具体用途,运营者都可能会触犯法律。数据是以孤岛的形式存在的,解决孤岛的直接方案就是把数据整合到一方进行处理。但是,现在这样做很可能是违法的,因为法律不允许运营者粗暴地进行数据聚合。如何合法地解决数据孤岛问题应该引起人工智能学者和从业者的深思,因为大数据面临的这个困境很可能就是导致人工智能下一个冬天的导火线。
要解决此困境,传统的方法已经行不通了,两个公司简单地交换数据在很多包括 GDPR 的法规中也是不允许的。首先,用户是原始数据的拥有者,在没有经用户同意的情况下,公司间是不能交换数据的。其次,数据建模使用的目的,在用户认可前也是不允许改变的。所以,过去许多数据交换的尝试都没成功,例如数据交易所,需要做出巨大的改变才能合规。同时,商业公司所拥有的数据往往都有巨大的潜在价值,甚至公司下属的部门之间都会考虑利益的交换,往往不会把数据拿出来与其他部门做简单的聚合。因而,即使在同一个公司内,数据也往往以孤岛的形式存在。
所以,我们倡议把研究的重点转移到如何解决大数据困境,即数据孤岛的问题上来。我们认为,下一步人工智能的重点会从以 AI 基础算法为中心的导向,转移到以保障安全隐私的大数据架构为中心的算法导向上。我们提出了一个可能的解决方案,叫做联邦学习(federated learning,亦被翻译成「联盟学习」或「联合学习」)。
联邦学习的概念在 2016 年由谷歌最先提出 [1],原本用于解决安卓手机终端用户在本地更新模型的问题。值得一提的是,另一种学习方法,joint learning[10],有时也被翻译成「联合学习」,它一般是指将不同来源的数据整合在一起用于多任务建模训练的场景中,其本质上是联合多个训练目标,而对数据的聚合方式和隐私没有要求。因此,联邦学习与这种联合学习是完全不同的概念。还有一种学习方法叫做「多任务学习」(multitask learning)[8,9],它是迁移学习的一个子方向,旨在有多个学习目标并部分共用数据的情况下,尽量多地利用共有模型部分来提高学习效果。多任务学习对数据安全和隐私也没有提出要求,而是一种机器学习算法。
联邦学习概述
什么是联邦学习呢?举例来说,假设有两个不同的企业 A 和 B,它们拥有不同的数据,比如企业 A 有用户特征数据,企业 B 有产品特征数据和标注数据。这两个企业按照 GDPR 准则是不能粗暴地把双方数据加以合并的,因为他们各自的用户并没有机会同意这样做。假设双方各自建立一个任务模型,每个任务可以是分类或预测,这些任务也已经在获得数据时取得了各自用户的认可。那么,现在的问题是如何在 A 和 B 各端建立高质量的模型。但是,又由于数据不完整(例如企业 A 缺少标签数据,企业 B 缺少特征数据),或者数据不充分(数据量不足以建立好的模型),各端有可能无法建立模型或效果不理想。联邦学习的目的是解决这个问题:它希望做到各个企业的自有数据不出本地,联邦系统可以通过加密机制下的参数交换方式,在不违反数据隐私保护法规的情况下,建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候,数据本身不移动,也不会泄露用户隐私或影响数据规范。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了「共同富裕」的策略。这就是为什么这个体系叫做「联邦学习」。
联邦学习的定义
为了进一步准确地阐述联邦学习的思想,我们将其定义如下:
当多个数据拥有方(例如企业) Fi (i=1\,…\, N) 想要联合他们各自的数据 Di 训练机器学习模型时,传统做法是把数据整合到一方,并利用数据 D={Di\, i=1\,…\, N}进行训练并得到模型 MSUM。然而,该方案由于涉及隐私和数据安全等法律问题通常难以实施。为解决这一问题,我们引入了联邦学习。联邦学习是指数据拥有方 Fi 在不用给出己方数据 Di 的情况下,也可进行模型训练得到模型 MFED 的计算过程,并能够保证模型 MFED 的效果 VFED 与模型 MSUM 的效果 VSUM 之间的差距足够小,即 |VFED-VSUM |<δ, 这里δ是任意小的一个正量值。
联邦学习的提出,是为了应对金融机构的痛点,尤其是像「微众银行」这样的互联网银行。其中一个实例是检测多方借贷。这在银行业,尤其是互联网金融行业一直是一个很头疼的问题。多方借贷是指某不良用户在一个金融机构借贷后还钱给另一个借贷机构,大量这种非法行为会让整个金融系统崩溃。要想发现这样的用户,传统的做法是金融机构去某中心数据库查询用户信息,而各个机构必须上传他们所有的用户信息,但这样做等于暴露了金融机构的所有重要用户隐私和数据安全,这在 GDPR 下是不允许的。在联邦学习机制下,没有必要建立一个中心数据库,而任何参与联邦学习的金融机构可以向联邦内的其他机构发出新用户查询请求,其他机构在不知道这个用户具体信息的前提下,回答该用户关于本地借贷的提问。这样既能保护已有用户在各个金融机构的隐私和数据完整性,同时也能完成查询多方借贷这个重要问题。
联邦学习的分类
在实际中,孤岛数据具有不同分布的特点,根据这些特点,我们提出了相对应的联邦学习方案。
考虑有多个数据拥有方,每个数据拥有方各自所持有的数据集 Di 可以用一个矩阵来表示。矩阵的每一行代表一个用户,每一列代表一种用户特征。某些数据集可能还包含标签数据。如果要对用户行为建立预测模型,就必须有标签数据。我们把用户特征叫做 X,把标签特征叫做 Y。比如,在金融领域,用户的信用是需要被预测的标签 Y;在营销领域,标签是用户的购买愿望 Y;在教育领域,标签则是学生掌握知识的程度等。用户特征 X 加标签 Y 构成了完整的训练数据 (X, Y)。但是,在现实中,往往会遇到这样的情况:各个数据集的用户不完全相同,或用户特征不完全相同。以包含两个数据拥有方的联邦学习为例,数据分布可以分为以下三种情况:
● 两个数据集的用户特征 (X1, X2, …) 重叠部分较大,而用户 (U1,U2, …) 重叠部分较小;
● 两个数据集的用户 (U1, U2, …) 重叠部分较大,而用户特征 (X1, X2, …) 重叠部分较小;
● 两个数据集的用户 (U1, U2, …) 与用户特征 (X1, X2, …) 重叠部分都比较小。
为了应对以上三种数据分布情况,我们把联邦学习分为横向联邦学习 (horizontal federated learning)、纵向联邦学习 (vertical federated learning) 与联邦迁移学习 (Federated Transfer Learning, FTL) [2](如图 1)。
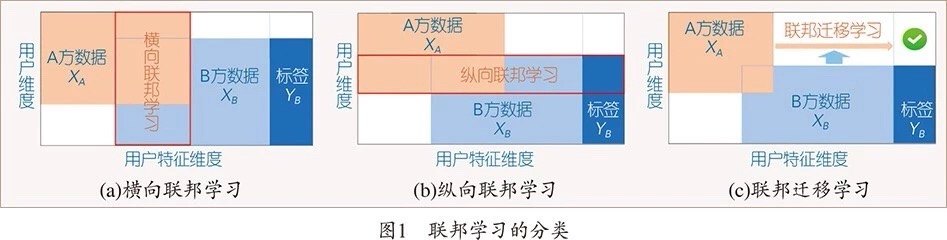
横向联邦学习 在两个数据集的用户特征重叠较多,而用户重叠较少的情况下,我们把数据集按照横向(即用户维度)切分,并取出双方用户特征相同而用户不完全相同的那部分数据进行训练。这种方法叫做横向联邦学习。比如有两家不同地区的银行,它们的用户群体分别来自各自所在的地区,相互的交集很小。但是,它们的业务很相似,因此,记录的用户特征是相同的。此时,我们就可以使用横向联邦学习来构建联合模型。谷歌在 2016 年提出了一个针对安卓手机模型更新的数据联合建模方案 [1]:在单个用户使用安卓手机时,不断在本地更新模型参数并将参数上传到安卓云上,从而使特征维度相同的各数据拥有方建立联合模型。
纵向联邦学习 在两个数据集的用户重叠较多而用户特征重叠较少的情况下,我们把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。这种方法叫做纵向联邦学习。比如有两个不同的机构,一家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民,因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。纵向联邦学习就是将这些不同特征在加密的状态下加以聚合,以增强模型能力。目前,逻辑回归模型、树型结构模型和神经网络模型等众多机器学习模型已经逐渐被证实能够建立在此联邦体系上。
联邦迁移学习 在两个数据集的用户与用户特征重叠都较少的情况下,我们不对数据进行切分,而利用迁移学习 [3] 来克服数据或标签不足的情况。这种方法叫做联邦迁移学习。比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习,来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
联邦学习的系统构架
我们以包含两个数据拥有方(即企业 A 和 B)的场景为例介绍联邦学习的系统构架。该构架可扩展至包含多个数据拥有方的场景。假设企业 A 和 B 想联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,企业 B 还拥有模型需要预测的标签数据。出于数据隐私保护和安全考虑,A 和 B 无法直接进行数据交换,可使用联邦学习系统建立模型。联邦学习系统构架由三部分构成,如图 2(a) 所示。
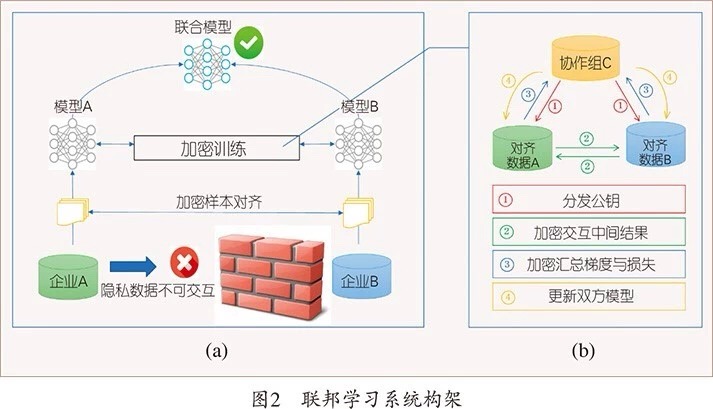
第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户,以便联合这些用户的特征进行建模。
第二部分:加密模型训练。在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步(如图 2(b) 所示):
● 第①步:协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密。
● 第②步:A 和 B 之间以加密形式交互用于计算梯度的中间结果。
● 第③步:A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把结果汇总给 C。C 通过汇总结果计算总梯度值并将其解密。
● 第④步:C 将解密后的梯度分别回传给 A 和 B,A 和 B 根据梯度更新各自模型的参数。
迭代上述步骤直至损失函数收敛,这样就完成了整个训练过程。在样本对齐及模型训练过程中,A 和 B 各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。
第三部分:效果激励。联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供数据多的机构所获得的模型效果会更好,模型效果取决于数据提供方对自己和他人的贡献。这些模型的效果在联邦机制上会分发给各个机构反馈,并继续激励更多机构加入这一数据联邦。
以上三部分的实施,既考虑了在多个机构间共同建模的隐私保护和效果,又考虑了以一个共识机制奖励贡献数据多的机构。所以,联邦学习是一个「闭环」的学习机制。
相关概念
作为一种全新的技术,联邦学习在借鉴一些成熟技术的同时也具备一定的独创性。
联邦学习与隐私保护的关系
联邦学习的特点使其可以被用来保护用户数据的隐私,但是它和大数据、数据挖掘领域中常用的隐私保护理论,如差分隐私保护理论 (differential privacy)[4] 与 k 匿名 (k-anonymity)[5] 等方法,还是有较大的差别。联邦学习与传统隐私保护方法的原理不同。联邦学习通过加密机制下的参数交换方式保护用户数据隐私,数据和模型本身不会进行传输,也不能反猜对方数据,因此在数据层面不存在泄露的可能,也不违反更严格的数据保护法案如 GDPR 等。而差分隐私理论、k 匿名和 l 多样化等方法是通过在数据里加噪音,或者采用概括化的方法模糊某些敏感属性,直到第三方不能区分个体为止,从而以较高的概率使数据无法被还原,以此来保护用户隐私。相较而言,联邦学习对用户数据隐私保护更为有用。
联邦学习与分布式机器学习的关系
横向联邦学习中的多方联合训练与分布式机器学习 (distributedmachine learning) 有部分相似。分布式机器学习涵盖了多个方面,包括把机器学习中的训练数据分布式存储、计算任务分布式运行、模型结果分布式发布等。参数服务器 (parameter server)[6] 是分布式机器学习中一个典型例子。它作为加速机器学习模型训练过程的一种工具,将数据存储在分布式的工作节点上,通过一个中心式的调度节点调配数据分布和分配计算资源,以便更高效地获得最终的训练模型。而横向联邦学习中的工作节点代表的是模型训练的数据拥有方,其对本地的数据具有完全的自治权限,可以自主决定何时加入联邦学习进行建模,联邦学习面对的是一个更复杂的学习环境。联邦学习强调模型训练过程中对数据拥有方的数据隐私保护,是一种应对数据隐私保护的有效措施。
联邦学习与联邦数据库的关系
联邦数据库系统 (federateddatabase system)[7] 是将多个不同的单元数据库进行集成,并对集成后的整体进行管理的系统。它的提出是为了实现对多个独立的数据库进行相互操作。联邦数据库系统对单元数据库往往采用分布式存储的方式,并且在实际中各个单元数据库中的数据是异构的,因此,它和联邦学习在数据的类型与存储方式上有很多相似之处。
应用实例
智慧金融
联邦学习作为一种保障数据安全的建模方法,在销售、金融等行业中的应用前景广泛。由于此行业受到知识产权、隐私保护、数据安全等因素影响,数据无法被直接聚合来进行机器学习模型训练。因此,借助联邦学习来训练一个联合模型不啻为好方法。
以智慧零售业务为例。智慧零售业务涉及到的数据特征有用户购买能力、用户个人偏好以及产品特点三部分。这三种数据特征很可能分散在三个不同的部门或企业。例如,银行拥有用户购买能力特征,社交网站拥有用户个人偏好特征,而购物网站则拥有产品特点的数据特征。在这种情况下,我们面临两大难题:第一,出于保护用户隐私以及企业数据安全等原因,银行、社交网站和购物网站三方之间的数据壁垒很难被打破,因此,智慧零售的业务部门无法直接把数据进行聚合并建模。第二,这三方的用户数据和用户特征数据通常是异构的,传统的机器学习模型无法直接在异构数据上进行学习。目前,这些问题使用传统的机器学习方法都没有得到切实有效的解决,它们阻碍了人工智能技术在社会更多领域中的普及与应用。
而联邦学习正是解决这些问题的关键。设想一下,在智慧零售的业务场景中,我们使用联邦学习与迁移学习对三方数据进行联合建模。首先,利用联邦学习的特性,我们不用导出企业数据,就能够为三方联合构建机器学习模型,既充分保护了用户隐私和数据安全,又为用户提供了个性化的产品服务,从而实现了多方共同受益。同时,我们可以借鉴迁移学习的思想来解决用户和用户特征数据异构的问题。迁移学习能够挖掘数据间的共同知识并加以利用,从而突破传统人工智能技术的局限性。可以说,联邦学习为我们建立一个跨企业、跨数据、跨领域的大数据 AI 生态提供了良好的技术支持。
智慧医疗
智慧医疗也在成为一个与人工智能相结合的热门领域。
IBM 的超级电脑「沃森」是人工智能在医疗领域最出名的应用之一,被中国、美国等多个国家的医疗机构用于自动诊断,主攻对多种癌症疾病的确诊以及提供医疗建议。然而,最近曝光的一份文件显示,沃森曾经在一次模拟训练中错误地开出了可能会导致患者死亡的药物。沃森医疗项目也因此备受打击。为何会误诊呢?沃森使用的训练数据本应包括病症、基因序列、病理报告、检测结果、医学论文等数据特征,但是在实际中,这些数据的来源远远不够,并且大量数据具有标注缺失问题。有人估计,把医疗数据放在第三方公司标注,需要 1 万人用长达 10 年的时间才能收集到有效的数据。数据的不足与标签的缺失导致机器学习模型训练效果不理想,这成为了目前智慧医疗的瓶颈所在。
如何才能突破这一瓶颈?设想,如果所有的医疗机构都联合起来,贡献出各自的数据,将会汇集成为一份足够庞大的数据,而对应的机器学习模型的训练效果也将有质的突破。实现这一构想的主要途径便是联邦学习与迁移学习。联邦迁移学习能做到此事主要有两个原因:第一,各个医疗机构的数据具有很大的隐私性,直接进行数据交换并不可行,联邦学习能够保证在不进行数据交换的情况下进行模型训练。第二,数据存在标签缺失严重的问题,而迁移学习可以用来对标签进行补全,扩大可用数据的规模,进一步提高模型效果。因此,联邦迁移学习必将在智能医疗上起到举足轻重的作用。
联邦学习和「企业数据联盟」
联邦学习既是一个技术规范,也是一个商业模式。当我们意识到大数据的作用时,首先想到的是把各自的数据聚到一起,通过远程的处理能力来产生结果,再把结果下载到本地加以使用。云计算应运而生。但是,在隐私和数据安全日益重要,公司利益和数据绑定越来越紧的时候,这一模式遇到了挑战。
联邦学习的商业模式为大数据的使用提供了一个新的范式。当各个机构的数据不足以建立理想的预测模型时,联邦学习机制使得参与的机构和企业可以在不交换数据的情况下共同建模。如果利用区块链等共识机制,联邦学习还可以建立合理的利益分配机制,使得数据拥有方,无论大小,都有动力加入数据联邦,并获得应有的利益(如图 3 所示)。我们认为,建立数据联邦的商业机制要和联邦学习的技术机制一同开展,推动建立各种行业的联邦学习标准和规范,使得联邦学习尽快落地。
展望
数据的孤岛分布以及对数据隐私监管力度的加强成为人工智能面临的挑战。联邦学习的产生为人工智能打破数据屏障和进一步发展提供了新的思路。它在保护本地数据的前提下让多个数据拥有方联合建立共有模型,从而实现了以保护隐私和数据安全为前提的互利共赢。期待在不久的将来,联邦学习能够帮助我们打破各领域、各行业的数据壁垒,在保护数据隐私和安全的前提下形成一个数据与知识共享的共同体,并向为数据联盟作出贡献的机构提供共识的奖励机制,最终把人工智能带来的红利落实到社会的各个角落。
参考文献
[1] McMahan H B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]// International Conference on Artificial Intelligence, 2017, 20(22): 1273-1282.
[2] 杨强 . GDPR 对 AI 的挑战和基于联邦迁移学习的对策 [J]. 中国人工智能学会通讯 , 2018,8:1-8.
[3] Pan S J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on knowledge and data engineering, 2010, 22(10): 1345-1359.
[4] Dwork C. Differential privacy: A survey of results[C]// International Conference on Theory and Applications of Models of Computation. 2008: 1-19.
[5] Sweeney L. k-anonymity: A model for protecting privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(05): 557-570.
[6] Ho Q, Cipar J, Cui H, et al. More effective distributed ml via a stale synchronous parallel parameter server[C]// Advances in Neural Information Processing Systems. 2013: 1223-1231.
[7] Sheth A P, Larson J A. Federated database systems for managing distributed, heterogeneous, and autonomous databases[J]. ACM Computing Surveys, 1990, 22(3): 183-236.
[8] Rich C. Multitask Learning[J]. Machine Learning,1997, 28(1): 41-75.
[9] Zhang Y and Yang Q. An Overview of Multi-Task Learning[J]. National Science Review (NSR), 2018, 5(1): 30-43.
[10] Finkel J R and Manning C D. Hierarchical joint learning: improving joint parsing and named entity recognition with non-jointly labeled data[C]//Proceedings of ACL'10. Association for Computational Linguistics, Stroudsburg, PA, USA, 2010: 720-728.
Report Story
留下你的评论